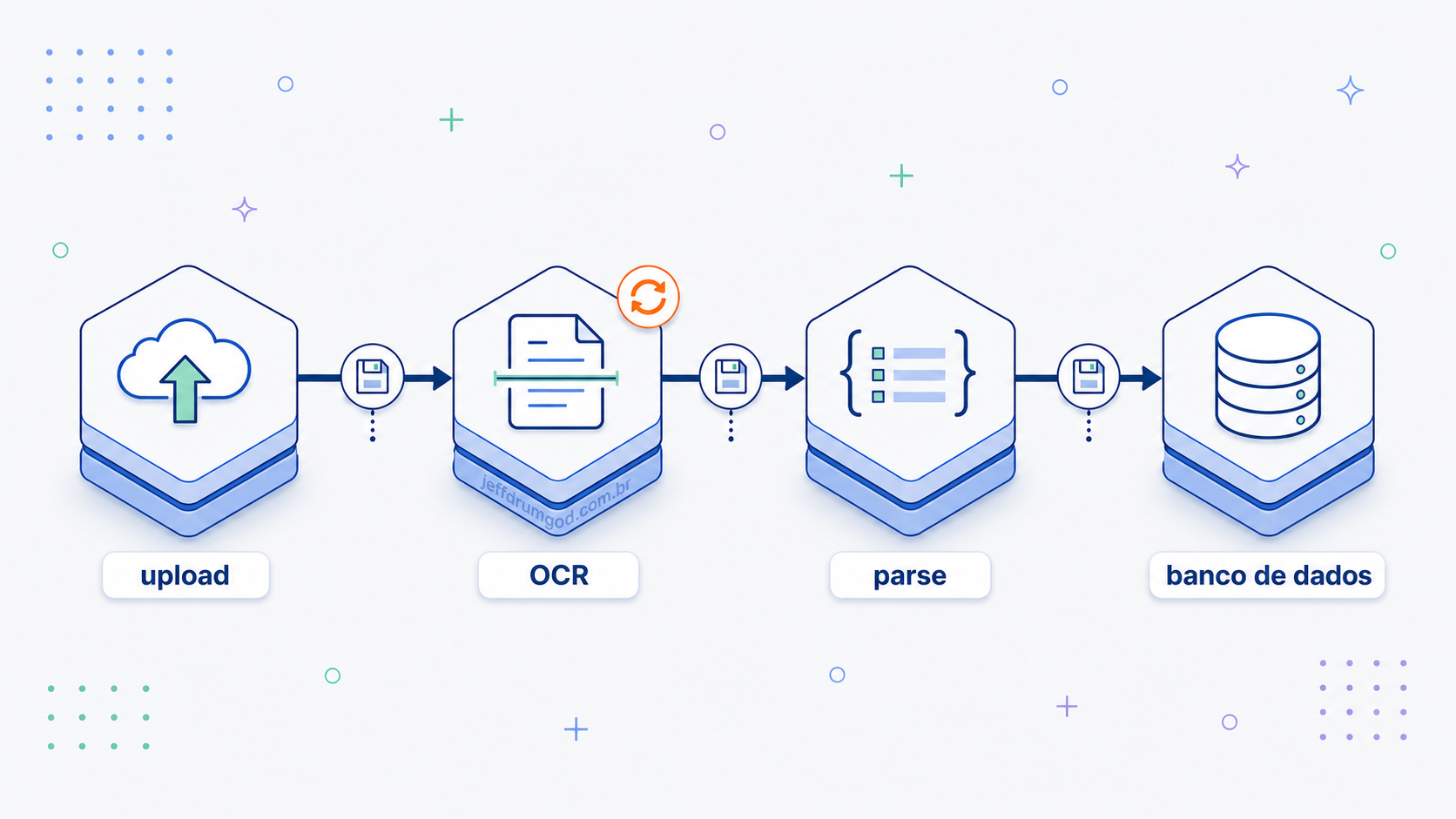
Você já escreveu aquele handler que faz quatro coisas seguidas: sobe um arquivo, chama uma API externa, processa o resultado, grava no banco, e torce pra nenhuma falhar no meio do caminho. Quando uma delas falha, o trabalho já feito vai junto e o usuário tem que recomeçar do zero. Existe um padrão que resolve isso e independe de framework: dividir o trabalho, persistir o estado entre os pedaços e deixar cada um falhar e retentar sozinho. Quem aprende isso para de escrever cron jobs frágeis e queue handlers ad-hoc, e começa a entregar pipelines que aguentam falha de rede e provedor instável em produção.
Vou mostrar o padrão com um exemplo que uso pra ensinar: um expense tracker que recebe a foto de um recibo, extrai os dados via OCR e grava como despesa. E vou implementar na Cloudflare Workflows, com os trade-offs que ninguém menciona em palestra de conferência. Esse site roda inteiro em Workers, com D1, R2, KV, Vectorize e Workers AI por baixo, então quando o pipeline já está no edge, Workflows é o orquestrador que não me obriga a sair de casa.
A abordagem ingênua: tudo num request só
Imagine o caso clássico: o usuário sobe a foto de um recibo, o Worker guarda a imagem, extrai o texto via OCR, parseia (merchant, total, data) e grava no banco. A primeira versão sai assim, e funciona em demo:
// src/index.ts — tudo num fetch handler (abordagem ingênua)
import { getUserId } from "./lib/auth"; // sessão autenticada (cookie + KV)
import { extractText, parseReceipt } from "./lib/receipt"; // wrappers sobre env.AI.run()
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const userId = await getUserId(request, env);
const form = await request.formData();
const file = form.get("receipt") as File;
// 1. sobe a imagem pro R2
const key = `receipts/${crypto.randomUUID()}`;
await env.BUCKET.put(key, file);
// 2. OCR via Workers AI (pode levar vários segundos num recibo grande)
const ocrText = await extractText(env, key);
// 3. parse estruturado com um LLM
const parsed = await parseReceipt(env, ocrText);
// 4. grava no D1
await env.DB.prepare(
"INSERT INTO expenses (user_id, merchant, total, date, receipt_key) VALUES (?, ?, ?, ?, ?)",
)
.bind(userId, parsed.merchant, parsed.total, parsed.date, key)
.run();
return Response.json({ ok: true });
},
};Funciona, até parar de funcionar, e em produção isso é só questão de tempo.
- O OCR demora oito segundos num recibo grande e a request fica aberta esse tempo inteiro. O app do cliente estoura o próprio timeout, ou o usuário desiste e fecha a tela, e o resultado se perde.
- O upload e o OCR rodaram, mas o
INSERTno D1 falhou. Você tem uma imagem no R2 sem nenhum registro apontando pra ela, um estado órfão. - O LLM de parse devolveu JSON malformado. Você joga exception, o usuário recebe 500, e o trabalho útil que já foi feito (upload + OCR) é descartado. A próxima tentativa refaz tudo do zero, inclusive a chamada cara de OCR.
O problema é fazer quatro coisas independentes dentro de uma única transação síncrona, sem nenhum lugar pra guardar o progresso parcial. Quando qualquer uma cai, a request inteira cai junto.

A virada: durable workflows
A solução é antiga em sistemas distribuídos e tem nome: durable execution. Em vez de uma function fazendo quatro coisas, você define um workflow: uma sequência de steps discretos, cada um persistido no momento em que termina. Se um step falha, só ele retenta. Se a infraestrutura cai entre steps, o orquestrador pega de onde parou quando voltar.
Pense numa linha de montagem. Se a estação 3 quebra, você não reinicia a fábrica inteira. Você conserta a estação 3 e a peça continua o trajeto. Cada estação tem um buffer de entrada (o estado vindo da estação anterior) e um buffer de saída (o estado pra próxima). É isso que um durable workflow faz com cada step do seu pipeline.
O padrão tem várias implementações maduras pra produção: Temporal, AWS Step Functions, Inngest, Trigger.dev, Restate, Azure Durable Functions e a Cloudflare Workflows, entre outras. Os detalhes mudam (modelo de hospedagem, linguagens suportadas, custo), mas a ideia é a mesma: você descreve uma série de steps e o orquestrador garante a durabilidade.
Redesenhando o expense tracker na Cloudflare Workflows
A reescrita separa duas responsabilidades. O Worker de entrada faz só o trabalho rápido e stateless: guarda o arquivo e dispara o workflow. O workflow durável faz o resto, lento e resiliente.
// src/index.ts — entrypoint rápido e stateless
import { getUserId } from "./lib/auth";
import { ReceiptWorkflow } from "./workflows/receipt";
export { ReceiptWorkflow }; // a classe precisa ser exportada pelo módulo principal
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const userId = await getUserId(request, env);
const form = await request.formData();
const file = form.get("receipt") as File;
// único trabalho síncrono: subir o arquivo e disparar o workflow
const key = `receipts/${crypto.randomUUID()}`;
await env.BUCKET.put(key, file);
const instance = await env.RECEIPT_WORKFLOW.create({
params: { userId, key },
});
// responde em poucos milissegundos; o pipeline roda atrás
return Response.json(
{ runId: instance.id, status: "processing" },
{ status: 202 },
);
},
};// src/workflows/receipt.ts — o workflow durável
import {
WorkflowEntrypoint,
type WorkflowStep,
type WorkflowEvent,
} from "cloudflare:workers";
import { NonRetryableError } from "cloudflare:workflows";
import { extractText, parseReceipt } from "../lib/receipt";
type Params = { userId: string; key: string };
export class ReceiptWorkflow extends WorkflowEntrypoint<Env, Params> {
async run(event: WorkflowEvent<Params>, step: WorkflowStep) {
const { userId, key } = event.payload;
const ocrText = await step.do(
"ocr-extract",
{
retries: { limit: 5, delay: "2 seconds", backoff: "exponential" },
timeout: "5 minutes",
},
async () => {
// o retorno do step é persistido pelo orquestrador
return extractText(this.env, key);
},
);
const parsed = await step.do(
"parse-structured",
{ retries: { limit: 3, delay: "1 second", backoff: "exponential" } },
async () => {
const data = await parseReceipt(this.env, ocrText);
if (!data.total) {
// resposta malformada do LLM não melhora com retry: falha de vez
throw new NonRetryableError("parse devolveu payload sem total");
}
return data;
},
);
const expenseId = await step.do(
"persist-db",
{ retries: { limit: 10, delay: "3 seconds", backoff: "linear" } },
async () => {
const row = await this.env.DB.prepare(
"INSERT INTO expenses (user_id, merchant, total, date, receipt_key) VALUES (?, ?, ?, ?, ?) RETURNING id",
)
.bind(userId, parsed.merchant, parsed.total, parsed.date, key)
.first<{ id: number }>();
if (!row) throw new Error("insert não retornou id");
return row.id;
},
);
await step.do("notify-user", async () => {
// push ou e-mail de "despesa pronta"
});
return { expenseId };
}
}E o binding no wrangler.jsonc, que é o que liga a classe ao env.RECEIPT_WORKFLOW:
{
"workflows": [
{
"name": "receipt-workflow",
"binding": "RECEIPT_WORKFLOW",
"class_name": "ReceiptWorkflow"
}
]
}O Worker de entrada responde em milissegundos, porque só sobe o arquivo e enfileira o workflow, e ninguém fica esperando o OCR. Como cada step retenta por conta própria, dá pra calibrar caso a caso: cinco tentativas com backoff exponencial no OCR, dez no insert (porque deadlock acontece) com backoff linear, três no parse. O retorno de cada step fica persistido, então se o workflow cair entre o parse-structured e o persist-db ele retoma com parsed já preenchido, sem refazer OCR nem chamar o LLM de novo. As duas etapas mais caras do pipeline rodam uma vez só. E o payload inicial fica disponível do primeiro ao último step, sem você serializar nada na mão.
Repare no NonRetryableError no parse. Nem toda falha merece retry: um JSON malformado do LLM vai falhar igual nas próximas cinco tentativas, então faz mais sentido falhar de uma vez e mandar o run pra investigação do que queimar tentativa à toa. Saber distinguir o que retenta do que desiste é metade do trabalho de desenhar um workflow.
O que muda quando algo quebra
Cenário: o serviço de OCR teve um pico e devolveu 503 três vezes seguidas. Na abordagem ingênua, o usuário viu um spinner por 30 segundos, recebeu um 500, e o arquivo que ele subiu sumiu. Ele tem que tentar de novo, rezando.
No workflow, o arquivo está seguro no R2 desde o segundo zero. O step ocr-extract tentou, falhou, esperou (backoff exponencial: 2s, 4s, 8s, 16s), tentou de novo, e numa das vezes passou. O usuário não viu nada, ou viu uma notificação quando a despesa apareceu na lista. O sistema absorveu a falha sem quebrar o contrato com quem estava do outro lado.
O ganho está aí: o usuário continua atendido mesmo quando um provedor externo cai às três da manhã, e o trabalho já feito não se perde. Escrever menos código é só efeito colateral.

Por que Workflows quando você já está na Cloudflare
O que a Cloudflare Workflows faz bem é deixar o padrão barato de adotar quando o seu compute já roda em Workers. O workflow é uma classe no mesmo projeto, acessa os mesmos bindings (R2, D1, KV, Workers AI) via this.env, e sobe no mesmo wrangler deploy. Não tem cluster pra manter nem fila externa pra provisionar.
No exemplo acima, o OCR usa Workers AI, a imagem está no R2 e a despesa vai pro D1. Os três já estão a um binding de distância dentro do workflow. Esse é o caso em que Workflows rende mais: quando o estado e o I/O do pipeline já moram no edge e você só quer durabilidade por cima, sem mudar de vizinhança.
Comparando os principais orquestradores
Cada orquestrador resolve durabilidade de um jeito. A tabela compara os principais e o ponto forte de cada um:
| Orquestrador | Hospedagem | Modelo de execução | Custo de entrada | Sweet spot |
|---|---|---|---|---|
| Cloudflare Workflows | Managed na rede da Cloudflare | Classe WorkflowEntrypoint com step.do |
Embutido no plano de Workers, com free tier | Pipelines cujo compute, dados e storage já vivem na Cloudflare (Workers, D1, R2, Workers AI) |
| Temporal | Self-hosted ou Temporal Cloud | Workers em qualquer linguagem (Go, TS, Java, Python) puxando tasks | Médio (cluster próprio) ou alto (Cloud) | Workflows complexos, longa duração, equipes que aceitam complexidade operacional |
| AWS Step Functions | Managed AWS | State machine declarativa (ASL) ou TS via CDK | Baixo (pay-per-transition) | Quem já está no AWS e integra com Lambda/SQS/DynamoDB |
| Inngest | Managed (também self-host) | Funções TS/Python com step.run |
Free tier generoso | Stack Node moderna com dev experience como prioridade |
| Trigger.dev | Managed (também self-host) | Tasks TS com await retry() e checkpoints |
Free tier, depois usage-based | Equipes Next.js/Remix querendo background jobs sem reinventar |
| Restate | Self-hosted (binário Rust) ou Restate Cloud | TS/Java/Kotlin com SDK durable | Baixo, simples de subir | Quem quer durable execution sem operar Cassandra/Postgres extra |
| Azure Durable Functions | Managed Azure | C#/JS/Python via Functions extension | Baixo (consumption plan) | Stack Microsoft, integração com o resto do Azure |
A escolha certa é a que combina com a stack que você já opera e com o tipo de workflow que precisa rodar. Se o seu backend está no AWS, Step Functions tira proveito da vizinhança do mesmo jeito que Workflows tira na Cloudflare.
Quando esse padrão vale a pena
Vale quando você tem:
- Chains de dois ou mais steps que podem falhar de forma independente.
- Jobs longos, acima do timeout natural da sua function.
- Integrações externas com SLA frágil: APIs de terceiros, providers de IA, gateways de pagamento.
- Side effects custosos que você quer evitar repetir: chamadas de LLM, OCR, conversão de vídeo.
- Necessidade de rastreabilidade, com cada run virando um registro auditável.
Não vale quando é um único call síncrono rápido (POST /login, GET /products), porque o overhead de instanciar workflow não compensa. Também não compensa pra trabalho fire-and-forget puro como logging ou métricas, onde uma fila simples (Cloudflare Queues, SQS, BullMQ) resolve mais barato. E se a latência fim-a-fim é medida em milissegundos pro usuário final, lembre que o workflow adiciona um hop de orquestração.
Outros casos onde o padrão se encaixa
Depois que você pega o padrão, passa a enxergar pipeline em todo canto:
- Moderação de imagem ou texto: upload → análise de NSFW → análise de marca registrada → quarentena ou liberação.
- Onboarding multi-step: criar conta → provisionar tenant → seedar dados de exemplo → mandar e-mail → cobrar o primeiro mês.
- Processamento de documento: PDF → extração de páginas → OCR por página → indexação vetorial → notificação.
- ETL leve: pull da fonte → normalizar → deduplicar → escrever no warehouse → atualizar dashboard.
- Pipelines de IA agêntica: planning → tool calls → consolidação → reflection → resposta.
Muda o domínio, muda a stack, mas o esqueleto é o mesmo, e qual orquestrador roda por baixo importa menos do que parece.
Trade-offs honestos
Ninguém te dá durable execution de graça. Você troca alguns problemas por outros, e vale saber quais antes de adotar:
- Debugging fica menos linear. Stack trace não conta a história inteira, e você precisa olhar o histórico de events da instância no painel do orquestrador. A curva de aprendizado é real.
- Lock-in de SDK. Trocar de Temporal pra Inngest, ou de Workflows pra Step Functions, não é grep & replace, porque a semântica de retry, checkpoint e versionamento muda.
- Idempotência vira obrigatória. Cada step pode rodar mais de uma vez (retry, replay durante recuperação). Se o seu insert cria duplicata em vez de upsert, você tem bug.
- Latência extra de orquestração. Cada step tem um custo de persistência. Workflow com 20 steps acumula esse overhead, então não use pra coisa que precisa ser instantânea.
- Versionamento é a parte delicada. Mudar a ordem ou a semântica dos steps com runs em andamento exige cuidado, e cada orquestrador tem sua estratégia. Deploy aditivo (steps novos no fim, parâmetros opcionais) é o caminho seguro.
- Custo financeiro. Em volume você paga por execução. Faça as contas antes de mover um pipeline de milhões de runs por dia.
Nenhum desses é deal-breaker. Todos são razões pra não jogar workflow em cima de qualquer endpoint só por modinha.
Fechamento
Durable execution é ideia antiga. Step Functions saiu em 2016, Temporal em 2019, e o conceito já aparecia em sistemas como o Cadence e o Workflow Foundation do .NET. O que mudou foi o custo de entrada: hoje dá pra ter durable steps sem manter um time de SRE só pra isso, e na Cloudflare sem sequer sair do projeto que você já deploya.
Se você tem na sua codebase um handler que faz três ou quatro coisas seguidas e torce pra nenhuma falhar, esse é o seu candidato. Quebra em steps, deixa o estado ser persistido entre eles e passa o resto pro orquestrador. Se o seu compute já está na Cloudflare, comece por Workflows e meça o resto.
Veja outros posts do blog sobre arquitetura no edge e práticas de backend.