Antes de você ler outro post genérico sobre "como começar um blog", vou te mostrar algo diferente: o blog que você está lendo agora foi construído em uma noite, é editável por IA via Model Context Protocol, serve menos de 100KB de HTML por post e roda inteiro no edge da Cloudflare, sem origem, sem container, sem k8s.
Neste artigo eu mostro a arquitetura completa, as decisões que tomamos (eu e meus agentes), e o que não funcionou no caminho.
O problema com blogs em 2026
A maioria dos blogs técnicos hoje cai em uma das três categorias:
- Static-site generators (Hugo, Jekyll): rápidos para servir, dolorosos para editar fora do editor. IA precisa abrir PR.
- Headless CMS (Contentful, Sanity, Strapi): editor confortável, mas latência alta (500ms+ por página) e API gateway extra.
- WordPress / Ghost: maduros, mas pesados, com plugin sprawl e ataques de XSS bem documentados.
Eu queria os três benefícios: edição rápida, performance de SSG e integração nativa com IA sem nenhum dos custos. A resposta acabou sendo simples: o edge. E ainda mais sendo programador por natureza, construir algo simples hoje em dia, é como brincadeira de criança.
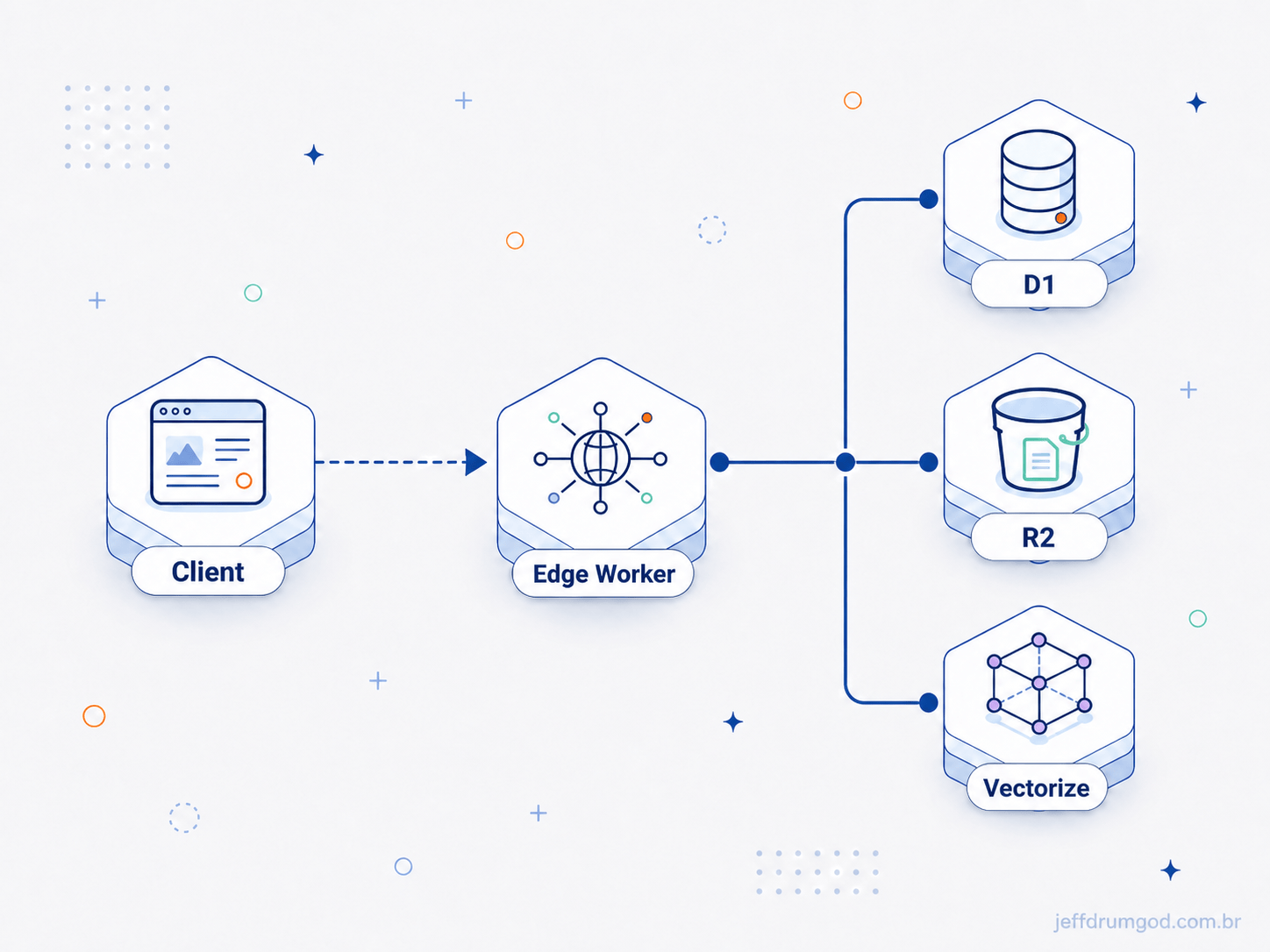
Stack em uma frase
Cloudflare Workers servem cada request, D1 guarda o conteúdo (Markdown), R2 guarda imagens, Vectorize indexa para busca semântica. Um servidor MCP deixa o ChatGPT (ou qualquer cliente) publicar/editar/traduzir posts via tool calls.
A receita inteira tem 5 partes:
| Camada | Tecnologia | Custo mensal* |
|---|---|---|
| Compute | Cloudflare Workers | $0 (tier free já é suficiente para começar) |
| DB | D1 (SQLite) | $0 — incluído |
| Storage | R2 | $0 — abaixo do free tier |
| Vector | Vectorize | $0 — abaixo do free tier |
| AI | Workers AI | $0 — neuron credits |
Para volume típico de blog pessoal (10-50k pageviews/mês). (obviamente dependendo do seu nicho de conteúdo e seu engajamento social, isso pode variar).
Schema mínimo viável
O schema D1 cabe em 100 linhas de SQL:
CREATE TABLE posts (
id INTEGER PRIMARY KEY AUTOINCREMENT,
uuid TEXT UNIQUE NOT NULL,
slug TEXT UNIQUE NOT NULL,
primary_locale TEXT NOT NULL DEFAULT 'en-US',
title TEXT NOT NULL,
excerpt TEXT,
body_md TEXT NOT NULL,
cover_image TEXT,
status TEXT CHECK(status IN ('draft','published','archived')),
published_at TEXT,
created_at TEXT DEFAULT (datetime('now')),
updated_at TEXT DEFAULT (datetime('now'))
);Note três decisões deliberadas:
- Markdown direto, não MDX: LLMs geram Markdown de forma natural. JSX em posts gerados por IA é frágil. Um caractere fora do lugar quebra o build inteiro.
uuidseparado deslug: o slug pode mudar (rebranding, fix de typo). O uuid não, e é a chave canônica para integrações externas.- Sem campo
html: HTML é derivado em runtime. Salvar HTML pré-renderizado parece otimização, mas torna invalidação de cache um pesadelo quando o renderer muda.
Tabelas auxiliares
As tabelas auxiliares podem fazer o que você espera: post_translations para i18n, post_tags (junção compartilhada com a tabela tags global do site), post_faqs para JSON-LD FAQPage, e post_revisions para auditoria. E o que mais você imaginar.
MCP server: a peça que muda tudo
O MCP server expõe as tools. E as que você mais vai usar, seriam algo como:
// posts.outline — gera outline a partir de tópico
{ topic: "Edge Functions vs Serverless tradicional" }
→ { title, hook, sections: [...], questions_to_answer: [...] }
// posts.suggest_metadata — analisa rascunho, sugere ajustes
{ body_md: "## Por que ...\n\n..." }
→ { slug, title, excerpt, seo_title, seo_description, tags, faqs }
// posts.publish — cria + publica em um request
{ title, body_md, tags, primary_locale, status: 'published' }
→ { uuid, slug, public_url, edit_url }Na prática, eu escrevo o miolo (a opinião, os dados coletados no teste ou estudo, a história), e o meu agente, ou o ChatGTP diretamente na interface chatgpt.com propõe a revisão organizada das ideias: SEO, FAQs, tags consistentes com o resto do site. Tempo médio entre rascunho e publicação cai consideravelmente, e sua ideia de conteúdo não cai no esquecimento.
No final, você pode ainda voltar e revisar o conteúdo, sem perder o timming daquela postagem.
Princípio: o autor do conteúdo escreve o que só ele sabe, seu conhecimento tácito. A IA faz o que qualquer modelo bem-treinado conseguiria escrever depois de ler o rascunho.
SEO + GEO + IA: três audiências, um post
O mesmo post precisa ser otimizado para:
- Google Search (SEO clássico), JSON-LD
BlogPosting,FAQPage, hreflang, sitemap. - Google AI Overviews / Perplexity (GEO — Generative Engine Optimization),
meta robotscommax-snippet:-1, max-image-preview:large, headings com IDs estáveis para citação por âncora. - LLMs de fundação que crawlam para treinar,
llms.txtindexado,posts.json(JSON Feed) comcontent_textcompleto machine-readable.
llms.txt incremental
A convenção llms.txt está virando o robots.txt da era LLM. Em vez de um único arquivo estático, eu sirvo um endpoint dinâmico que lista os 50 posts mais recentes:
# jeffdrumgod.com.br — Blog
> Feed JSON: https://jeffdrumgod.com.br/posts.json
## Posts recentes
- [Como construímos um blog MCP-native...](https://...) — Receita técnica completa.
- [Hello World!](https://...) — Apenas um exemplo!O crawler de IA pega o índice, segue o link, lê o post completo no posts.json (que entrega Markdown bruto, sem ruído visual). Resultado: a IA cita você com mais precisão.
Headings com âncora estável
Cada <h2> e <h3> ganha um id derivado do texto, com <a href="#id" class="post-anchor">#</a> ao lado. Isso permite que LLMs façam citações com URL + fragmento (/blog/post#secao-x), exatamente como o Wikipedia faz.
Performance: 100KB por post
Números de exemplos de post (medido com curl -w):
- HTML: ~95KB (gzip)
- TTFB médio: 60ms (origem); ~25ms (CDN HIT)
- LCP image (cover): pré-carregada com
fetchpriority="high" - Zero JavaScript de runtime para o blog (View Transitions é opcional)
O segredo: render Markdown server-side com marked + shiki (engine JavaScript). Sem hidratação, sem framework client. O HTML que sai do Worker é o HTML final.
Trade-offs honestos
Nada disto é mágica. As decisões custam:
- D1 não é Postgres. Sem JSONB, sem full-text search robusto (use Vectorize como substituto), sem extensions. Aceitei porque um blog não precisa disso obrigatoriamente.
- Editor é texto puro com preview. Sem WYSIWYG. Pra mim é feature; pode não ser pra você.
- Workers AI tem context window de 8k tokens no llama-3.1-8b (no caso, no worker). Então, tradução automática cria "chunks" do body, fazendo pedaços de ~3500 chars. Funciona, mas fronteira de seção pode confundir o modelo.
- Cache invalidation depende de purge manual via API CF. Precisei construi mecanismo e regras do que precisa ser limpo e quanto, como em
posts.publish/update/delete.
Próximos passos, ideias
No backlog para o segundo trimestre:
- OG image dinâmico via Satori + resvg em Worker — gerar uma capa de social com título sobreposto nas cores base e estilo do tema do blog.
- Comentários self-hosted — provavelmente Cusdis ou Giscus, mas estou olhando uma versão MCP-native onde leitor faz pergunta e a resposta vai para o
/QnAnamespace. - Related posts via Vectorize — já tenho o índice; falta expor apenas no template (atualmente atrás de um feature flag).
Se você está construindo algo parecido — ou quer trazer essa stack pro seu produto — agende uma conversa. Ou me siga em @jeff_drumgod.